Friday Fixes: AEO ≠ Agent-Ready
A couple of weeks back I published an SEO and AEO audit of this site. It found a Cloudflare setting silently blocking every AI crawler, broken RSS links, a missing sitemap, no structured data, no llms.txt — twenty issues, all shipped in one session. The audit felt thorough. The post landed well.
Then I ran the same site through Cloudflare's new isitagentready.com checker.
It gave vibescoder.dev a 25. Level 1. "Basic Web Presence."
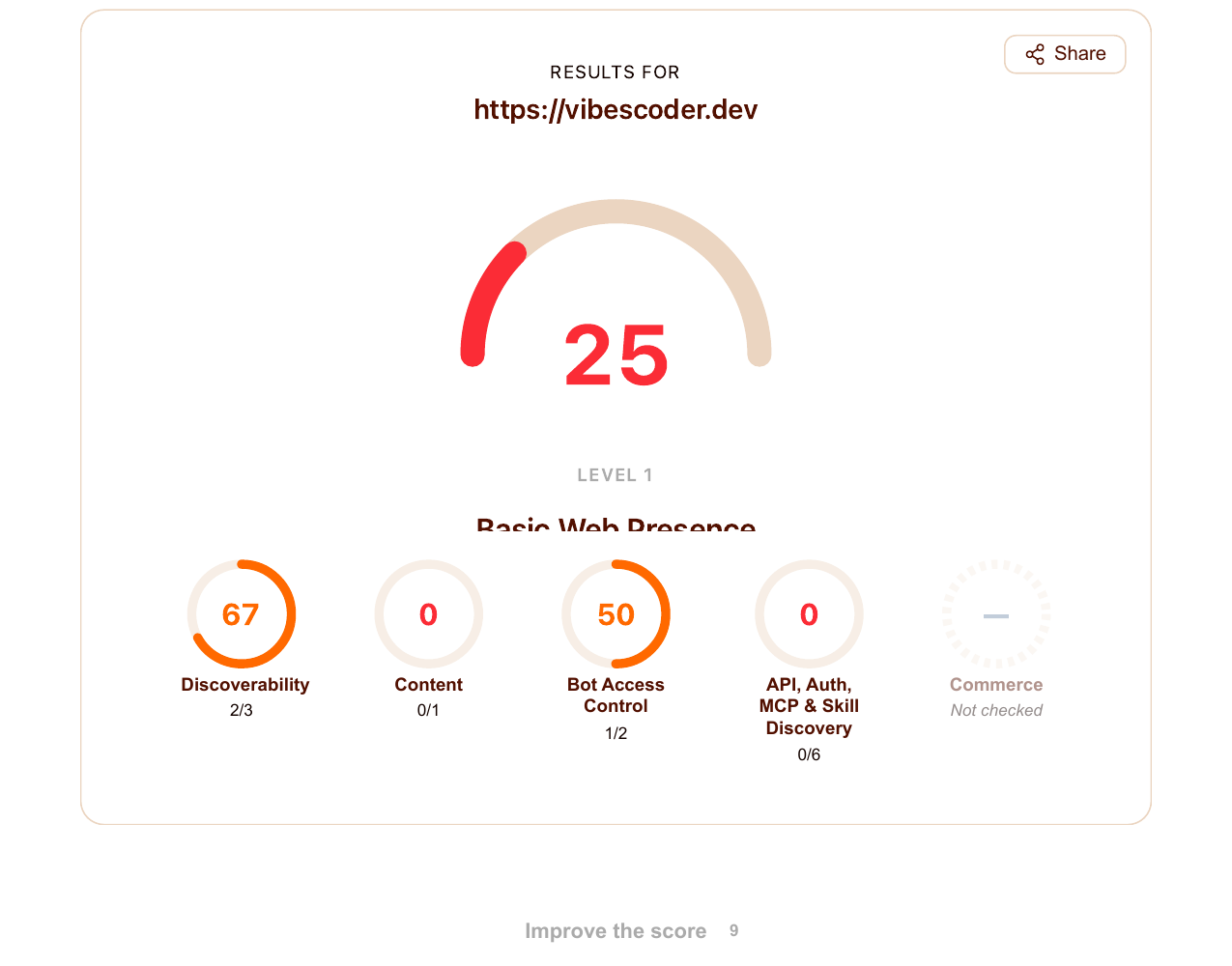
My first reaction was defensiveness — we just did this. My second reaction was suspicion of the tool — Cloudflare has a commercial interest in selling agent-readiness as a category. My third reaction was to do what I should have done first: read the report carefully and see what it was actually measuring.
The answer is interesting enough that it changes how I think about the AEO category itself. AEO and "agent-ready" are two emerging competencies. They are related. They are not the same. And right now, almost nobody is doing both.
The two audits were asking different questions
The AEO audit I ran a couple of weeks back asked:
Can ChatGPT, Perplexity, Google AI Overviews, and Claude find, read, and cite my content?
That's a content discoverability question. The remediation is about being indexable, parseable, and attributable: robots.txt, sitemaps, structured data, llms.txt, full-content RSS, canonical URLs, heading anchors. It's the 2024–2025 problem with established best practices.
Cloudflare's checker asks a much narrower, more forward-looking question:
Can autonomous agents programmatically discover and invoke services on this site?
That's an agent-actionability question. The remediation is about being callable: Link headers advertising resources (RFC 8288), markdown content negotiation, API catalogs (RFC 9727), OAuth/OIDC discovery (RFC 8414), OAuth Protected Resource metadata (RFC 9728), MCP Server Cards (SEP-2127), Agent Skills indexes, WebMCP tool registrations. It's the 2026 problem and most of the standards are still in draft.
Those two questions overlap on maybe three of thirteen checks. The other ten are testing things our audit didn't think to look at — and several of them legitimately don't apply to a read-only blog.
The category-by-category breakdown
| Cloudflare category | Score | What it checks | In our AEO audit? |
|---|---|---|---|
| Discoverability | 2/3 | robots.txt, sitemap, Link response headers (RFC 8288) | Partial — we shipped robots/sitemap; Link headers never came up |
| Content | 0/1 | Markdown content negotiation (Accept: text/markdown) | No — we solved the need with llms-full.txt, not the protocol |
| Bot Access Control | 1/2 | AI bot rules in robots.txt, Content Signals in robots.txt, Web Bot Auth | Partial — we explicitly rejected Content Signals |
| API, Auth, MCP & Skill Discovery | 0/6 | API Catalog, OAuth/OIDC discovery, OAuth Protected Resource, MCP Server Card, Agent Skills index, WebMCP | No — none of this was in scope |
| Commerce | n/a | x402, MPP, UCP, ACP payment protocols | Not applicable |
Twenty fixes in our AEO audit. Thirteen checks in Cloudflare's. Overlap: three. That's the entire story of the score gap in one sentence.
What Cloudflare caught that we genuinely missed
Two findings are real misses — gaps our audit didn't think to look for, with cheap fixes, that I shipped today.
1. Link response headers (RFC 8288)
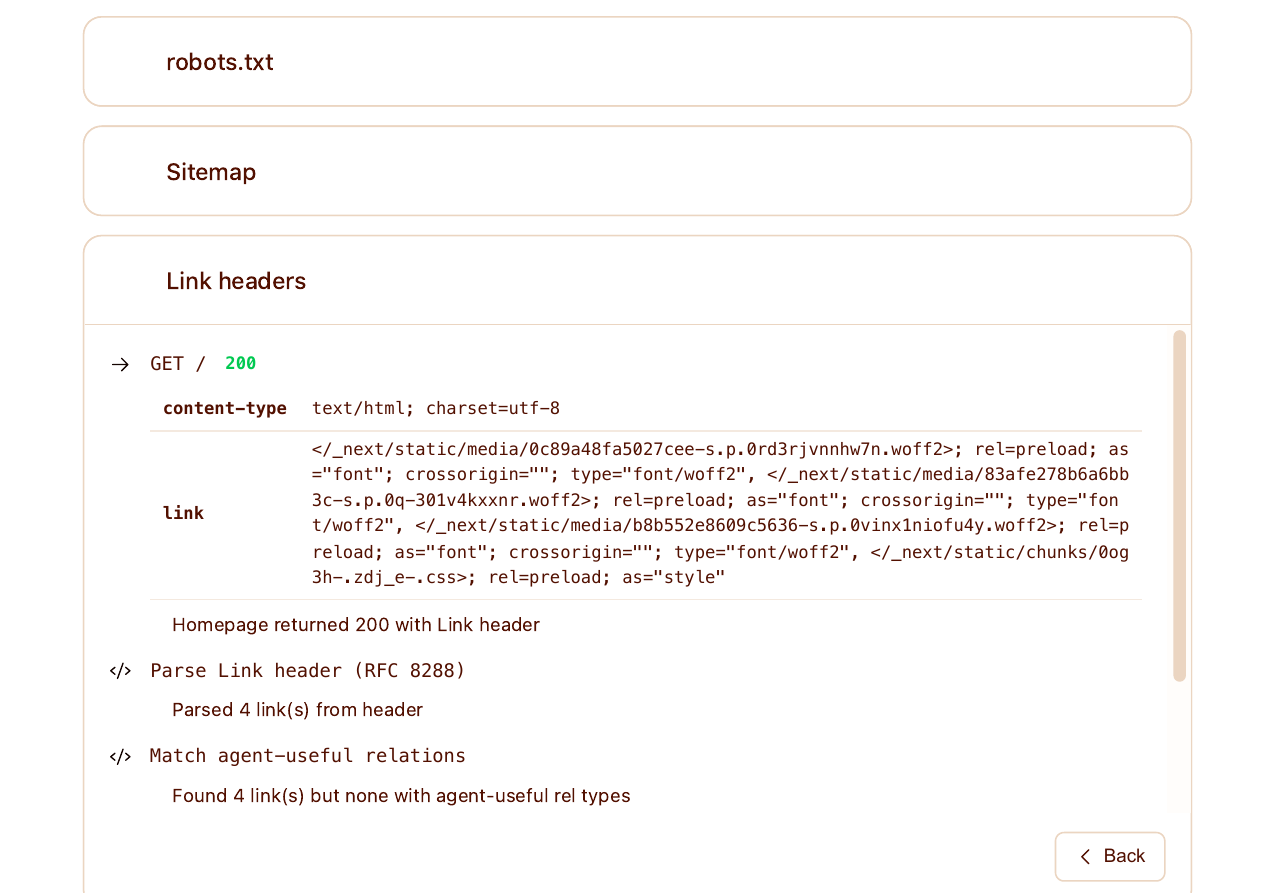
Our site already sends Link: response headers — but only the auto-generated rel="preload" entries for fonts and CSS that Next.js and Cloudflare's Early Hints feature inject. Cloudflare's checker parsed four link relations on the homepage and found none of them point agents at anything useful.
Link: is one of the older agent-discovery patterns (RFC 8288 dates to 2017), and it's how a passing crawler asks the homepage "what do you have for me?" The remediation is to advertise the resources you already publish:
// next.config.ts
const LINK_HEADER = [
'</llms.txt>; rel="describedby"; type="text/plain"',
'</llms-full.txt>; rel="alternate"; type="text/plain"; title="Full content for LLMs"',
'</feed.xml>; rel="alternate"; type="application/rss+xml"; title="RSS feed"',
'</sitemap.xml>; rel="sitemap"; type="application/xml"',
].join(", ");Six lines in next.config.ts. The header coexists with the preload Link headers Next.js auto-emits — multiple Link values on one response is explicitly valid per RFC 8288 §3. Verify after deploy:
curl -sI https://vibescoder.dev/ | grep -i ^linkThis is a real miss. Our audit's framing was "make content discoverable to AI agents," and Link headers genuinely fit that — they're a homepage-level pointer to the very llms.txt and RSS feed we'd already created. The auditor agent prioritized the files and missed the signpost.
2. Markdown content negotiation
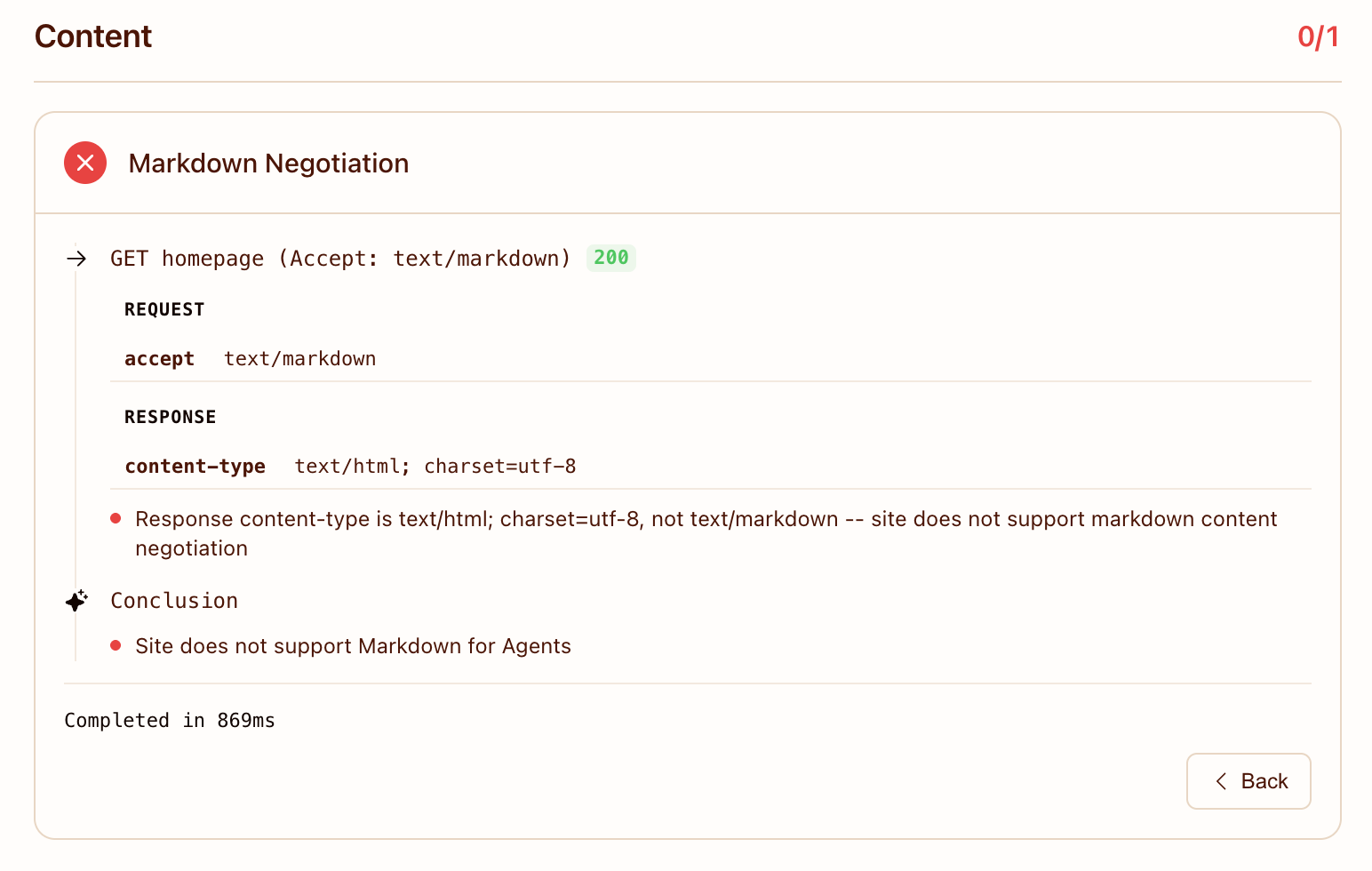
Cloudflare sends Accept: text/markdown to the homepage. The server returns text/html. Fail.
The interesting nuance here is that we already solved the underlying problem — /llms-full.txt is a single endpoint that returns every post's full content as plaintext. An agent that wants the markdown version of vibescoder.dev's corpus has had a working answer since the AEO audit. But Cloudflare's checker doesn't know about llms-full.txt because it doesn't dereference Link headers (yet) or llms.txt (yet). It tests the protocol it tests: per-URL Accept negotiation.
The fix is content negotiation in middleware:
// src/middleware.ts
if (pathname.startsWith("/posts/") && !pathname.endsWith("/raw")) {
const accept = request.headers.get("accept") ?? "";
if (prefersMarkdown(accept)) {
const url = request.nextUrl.clone();
url.pathname = pathname.replace(/\/?$/, "") + "/raw";
const res = NextResponse.rewrite(url);
res.headers.set("Vary", "Accept");
return res;
}
}The rewrite targets a new route handler at /posts/[slug]/raw/route.ts that returns the raw MDX with Content-Type: text/markdown; charset=utf-8. The Vary: Accept header tells shared caches to keep the HTML and markdown representations separate — without it, the first response wins and pollutes the cache for everyone else.
One subtle bit: the Accept parser respects q-values. Browsers default to something like text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8. A naive accept.includes("text/markdown") check would never match anyway, but the more useful guarantee is that if some future browser starts sending text/markdown;q=0.5,text/html;q=1.0, we still serve HTML. Markdown only wins when it's explicitly preferred.
Try it after deploy:
curl -sH "Accept: text/markdown" https://vibescoder.dev/posts/your-ai-strategy-has-a-blind-spot | head -20You should see a markdown document with a frontmatter-ish header (title, description, author, date, canonical URL, tags) followed by the post body.
What Cloudflare flagged that we deliberately disagree with
One overlap finding is a values disagreement, not a gap.
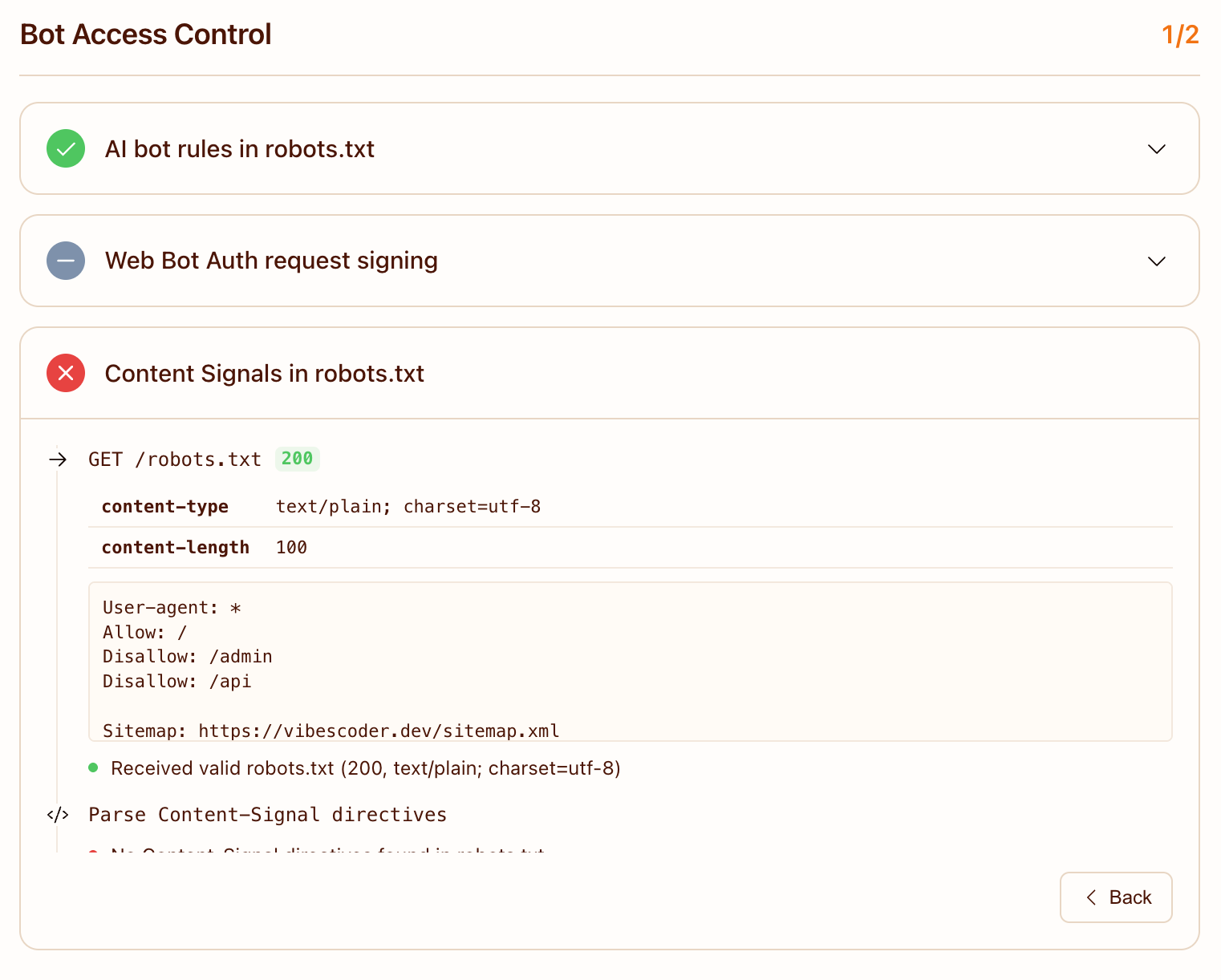
Cloudflare's checker wants Content-Signal: directives in robots.txt (e.g., Content-Signal: ai-train=no, search=yes, ai-input=no). Last week's audit post explicitly argued against this:
"The Content Signals option keeps a
Content-Signal: ai-train=nodirective, which tells AI crawlers not to use your content for model training. That sounds reasonable — but for a personal blog trying to maximize reach, being in the training corpus means AI models are more likely to know about you and reference your ideas."
The checker rewards having Content Signals, even ones that say "no training." If I wanted the point, I'd add Content-Signal: ai-train=yes, search=yes, ai-input=yes — which matches our actual policy. I'm probably going to do that. The point isn't whether to grant training rights; it's whether to declare a policy. Silence is currently being read as "no signal," not "yes by default."
What's penalizing the score but doesn't apply to a blog
Six of thirteen checks are in the API, Auth, MCP & Skill Discovery bucket. We score 0/6 on all of them.
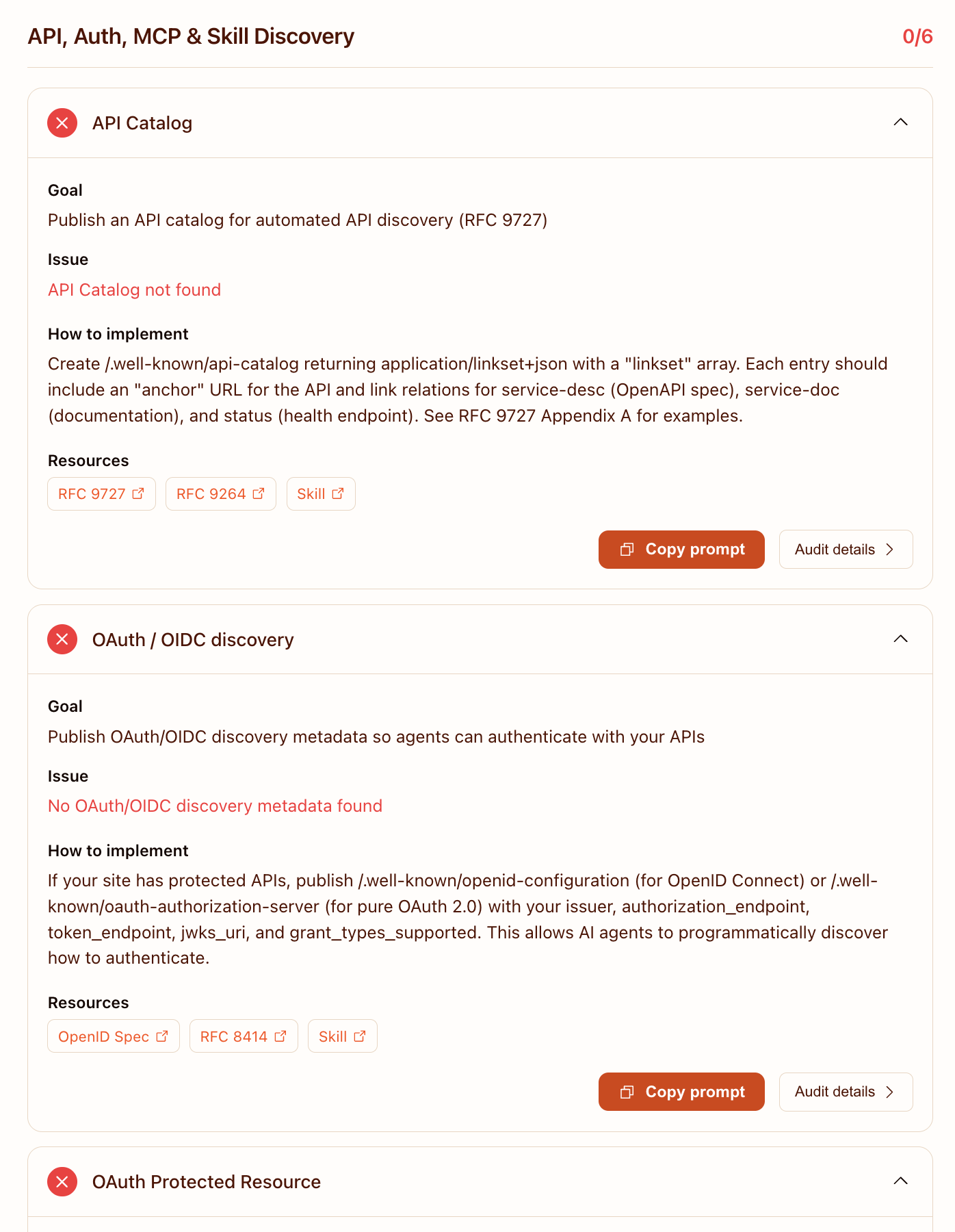
The list:
| Check | What an agent would do with it | Applies to vibescoder.dev? |
|---|---|---|
API Catalog (RFC 9727, /.well-known/api-catalog) | Discover the site's public APIs | No public APIs |
OAuth/OIDC discovery (RFC 8414, /.well-known/openid-configuration) | Learn how to authenticate | No public auth surface |
OAuth Protected Resource (RFC 9728, /.well-known/oauth-protected-resource) | Discover which OAuth servers can issue tokens for the site's resources | No protected resources |
MCP Server Card (SEP-2127, /.well-known/mcp/server-card.json) | Connect to an MCP server hosted by the site | No MCP server |
Agent Skills index (/.well-known/agent-skills/index.json) | Browse available agent skills | No agent skills published |
WebMCP (navigator.modelContext.provideContext()) | Invoke browser-side tools the page exposes | No browser-side tools |
These aren't bugs. They're the checker scoring vibescoder.dev as if it should expose a programmatic surface — APIs, OAuth, MCP, skills, browser tools. A read-only personal blog should not. The Commerce category (0/0) is correctly excluded from scoring because no e-commerce signals were detected; arguably the MCP/Auth/Skills bucket should be too, but it's not.
If/when this blog grows an agent-actionable surface — say, an MCP server that lets agents subscribe to posts, or an API that exposes analytics under OAuth — those zeros become meaningful and most of them get closed by a single .well-known file per protocol. Until then, they're noise.
Why both audits are correct
This is the part that surprised me.
AEO is about being read. It optimizes for the model that consumes content: a crawler, an answer engine, an AI assistant summarizing your work into a response. The remediation is on the publishing side. The unit of value is citation.
Agent-ready is about being used. It optimizes for the agent that acts on your site: invoking tools, authenticating to APIs, exchanging value via payment protocols, registering capabilities through MCP or WebMCP. The remediation is on the API/protocol side. The unit of value is invocation.
Most sites today need AEO. Most sites today don't need most of "agent-ready." A blog needs the first; an enterprise SaaS app probably needs both; an internal tool probably needs only the second. The frustration with the score is that Cloudflare's checker doesn't yet distinguish site class — it scores every URL against every protocol — but the underlying competencies are real and distinct.
The right mental model isn't "I scored 25/100, I have work to do." It's "this audit measured a competency I haven't built and probably don't need yet — except for these two findings that genuinely belong in the content-discoverability bucket I thought I'd already finished."
That's a more useful conclusion than either "Cloudflare is gatekeeping a fake category" or "we missed everything."
What shipped
Three commits, one repo, all linked back to specific Cloudflare findings.
| Fix | Cloudflare check | What |
|---|---|---|
Link response headers in next.config.ts (eb51e85) | Discoverability — Link headers | Advertise llms.txt, llms-full.txt, RSS, sitemap from every response |
Markdown negotiation for posts in middleware.ts + new /posts/[slug]/raw/route.ts (eb51e85) | Content — Markdown Negotiation (post URLs) | Serve raw MDX as text/markdown when Accept prefers it |
| Markdown negotiation extended to homepage (7c55e3c) | Content — Markdown Negotiation (root URL) | Rewrite /, /about, /tags to /llms.txt when Accept prefers markdown |
Deliberately not shipped: Content Signals in robots.txt (values disagreement, may add ai-train=yes later), all six API/Auth/MCP/Skills well-knowns (out of scope for a read-only blog).
The rescan: 25 → 33
After the deploy landed, I re-ran the same isitagentready.com check.
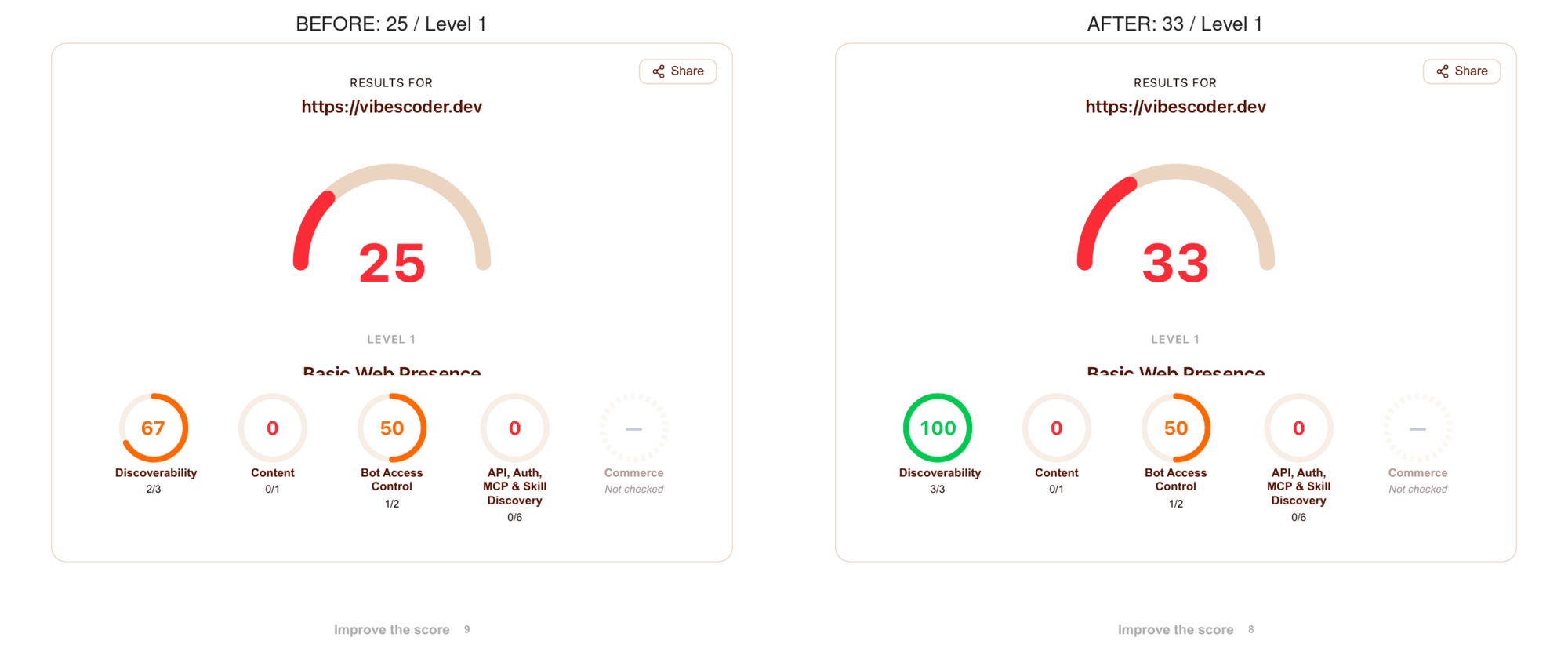
Discoverability went from 2/3 to 3/3. The Link headers check is now green, with the audit detail showing the <llms.txt>; rel="describedby", <llms-full.txt>; rel="alternate", RSS, and sitemap entries Cloudflare parsed out of our response.
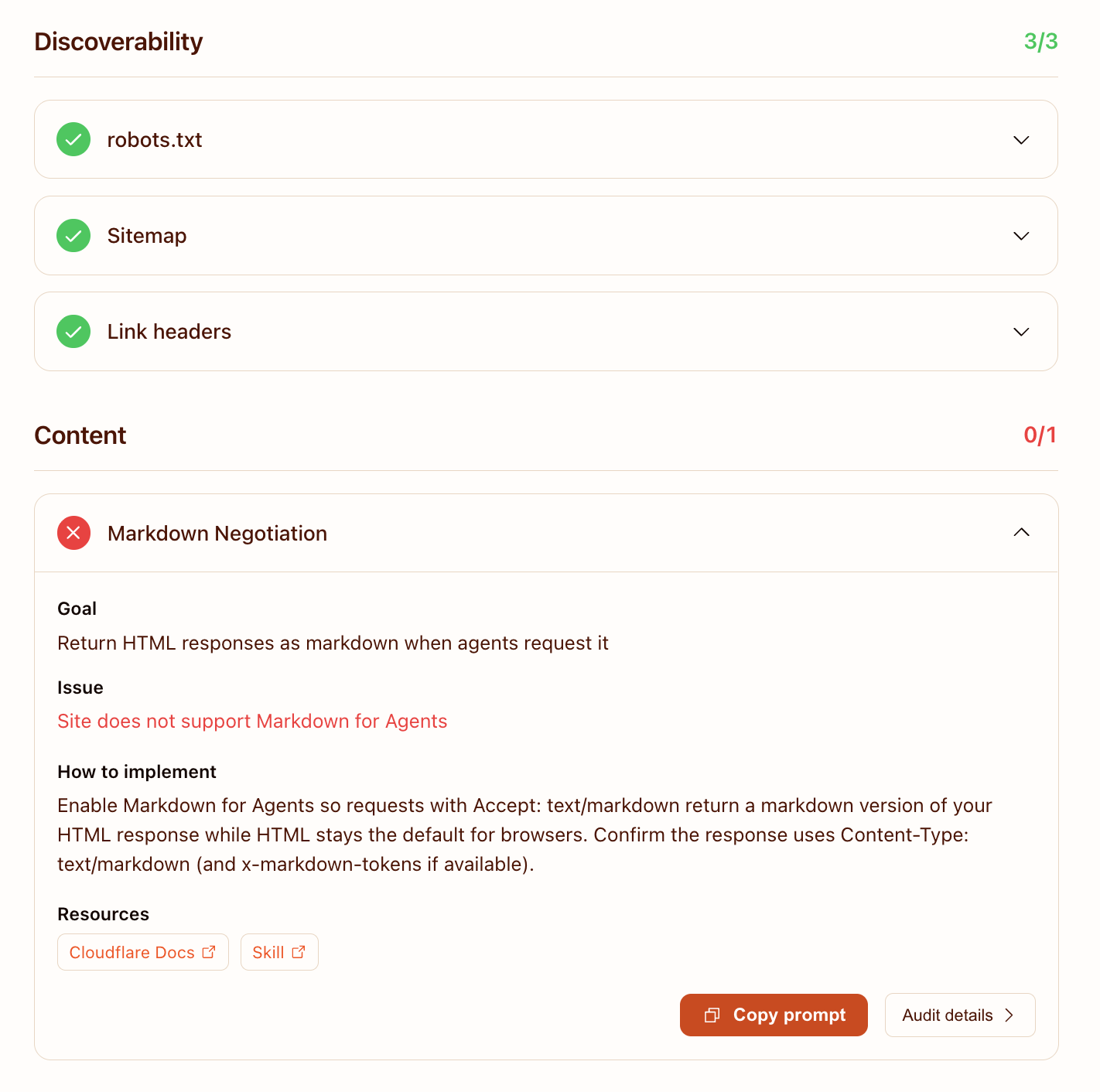
Content stayed at 0/1. That one surprised me — the markdown negotiation fix works (curl -H 'Accept: text/markdown' https://vibescoder.dev/posts/your-ai-strategy-has-a-blind-spot returns a clean text/markdown response with the post body). But Cloudflare's checker only probes GET / for markdown, not /posts/<slug>. The fix was real; it just wasn't where the checker looks.
Fifteen minutes later, a third commit — 7c55e3c — extended the middleware to also rewrite /, /about, and /tags to /llms.txt when Accept prefers markdown. /llms.txt is already a hand-curated markdown summary of the site, so it's the right answer for an agent asking the root URL in markdown:
if (pathname === "/" || pathname === "/about" || pathname === "/tags") {
const accept = request.headers.get("accept") ?? "";
if (prefersMarkdown(accept)) {
const url = request.nextUrl.clone();
url.pathname = "/llms.txt";
const res = NextResponse.rewrite(url);
res.headers.set("Vary", "Accept");
res.headers.set("Content-Type", "text/markdown; charset=utf-8");
return res;
}
}That should push the next rescan to roughly 39 / Level 1 — Content 1/1, leaving only the deliberate Content Signals abstention and the six out-of-scope API/Auth/MCP/Skills checks as the remaining gap.
The practical lesson buried inside the score: automated checkers test the protocol at a specific URL, not the capability across your site. Our /posts/<slug> markdown negotiation was correct from the first deploy, but the checker probes /. The implementation has to meet the probe where the probe lives.
What's left and why we're stopping there
With the homepage extension, every Cloudflare finding that maps onto a content-discoverability competency is now closed. What remains:
| Remaining check | Score | Why we're not shipping a fix |
|---|---|---|
| Content Signals in robots.txt | 0/1 | Deliberate — we don't want to declare ai-train=no, and the checker doesn't distinguish "opt-in" from "present." Likely to add Content-Signal: ai-train=yes, search=yes, ai-input=yes once the directive grammar settles |
| Web Bot Auth request signing | n/a | Cloudflare Enterprise feature; not applicable on the free tier |
| API Catalog (RFC 9727) | 0/1 | No public API |
| OAuth/OIDC discovery (RFC 8414) | 0/1 | No public auth surface |
| OAuth Protected Resource (RFC 9728) | 0/1 | No protected resources |
| MCP Server Card (SEP-2127) | 0/1 | No MCP server |
| Agent Skills index | 0/1 | No agent skills published |
| WebMCP browser tools | 0/1 | No browser-side tools |
The last six all live in the agent-actionability competency — the "can an agent do something here" question. For a read-only personal blog, leaving them empty is the correct answer; shipping placeholder .well-known files just to satisfy a scorecard would be cargo-culting.
How I'd update that earlier audit
The earlier AEO audit post framed the work as "20 issues across 4 severity levels — done." That framing was correct for the question we asked. What I'd add today, in light of the Cloudflare audit:
- AEO has a sibling discipline called agent-readiness. It's distinct, not a superset.
- Two of the AEO improvements really should have included Link headers and content negotiation. They live on the boundary between the two competencies, and our auditor agent missed them because it was framed entirely around content discovery.
- Tools like isitagentready.com are useful even when the score is misleading. The score is calibrated for sites with programmatic surfaces. The individual findings are still surfacing real protocol-level gaps that a content-only audit can't see.
The audit you run depends on the question you ask. The question you ask depends on the framing of "what does it mean for an AI to consume my site?" The interesting realization from running both audits back-to-back is that there are now at least two good answers to that question, and they're going to keep diverging as the protocols underneath each one mature.
By the Numbers
- 25 → 33 Cloudflare agent-readiness score (and ≈39 expected on the next scan once the homepage markdown extension lands)
- 67% → 100% Discoverability after the Link headers fix — the visible scorecard win
- 13 checks in the Cloudflare audit, of which 3 overlap with our original AEO audit
- 20 fixes in our original AEO audit; 0 of them targeted Link headers or markdown negotiation
- 2 genuine misses Cloudflare caught and we didn't: Link headers, content negotiation
- 1 values disagreement (Content Signals — we deliberately don't declare
ai-train=no) - 6 / 13 checks in the API/Auth/MCP/Skills bucket — all 0/6, all out of scope for a read-only blog
- 3 commits shipped today (two in the initial fix, one to extend markdown negotiation to the homepage after the checker only probed
/) - 6 lines of config for the Link header fix
- ~65 lines of middleware + route handler for markdown negotiation across both commits
- 1 lesson about automated checkers: they test the protocol at a specific URL, not the capability across the site